//必须指明主主键信息,才能明确到行,如果信息不能确定到具体的行的话,只能锁表,如id <> 3, //也会直接锁表. FOR UPDATE 仅适用于InnoDB,且必须在事务区块(BEGIN/COMMIT)中才能生效。 select * from tableA where id=*** FOR UPDATE
top//每隔5秒显式所有进程的资源占用情况 top -d 2//每隔2秒显式所有进程的资源占用情况 top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名) top -p12345 -p6789//每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况 top -d 2 -c -p123456//每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数
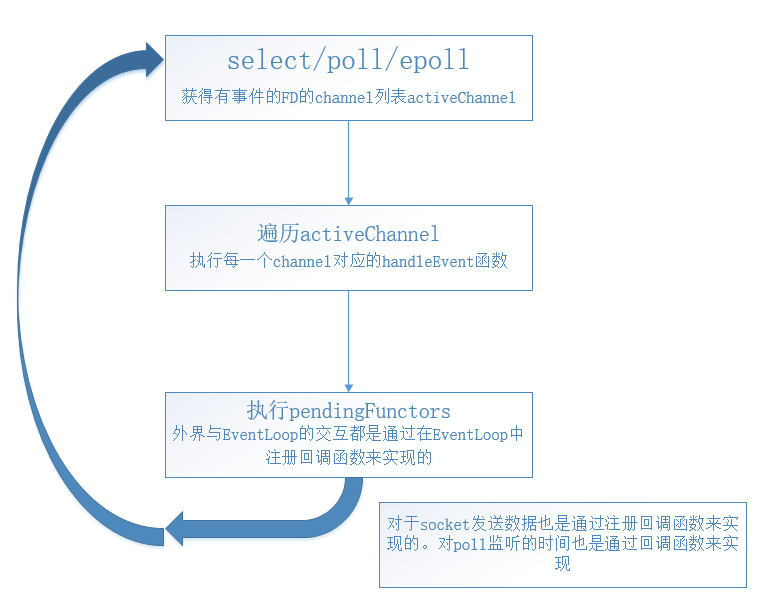
//关闭连接 void TcpConnection::forceCloseInLoop() { loop_->assertInLoopThread(); if (state_ == kConnected || state_ == kDisconnecting) { // as if we received 0 byte in handleRead(); handleClose(); } }
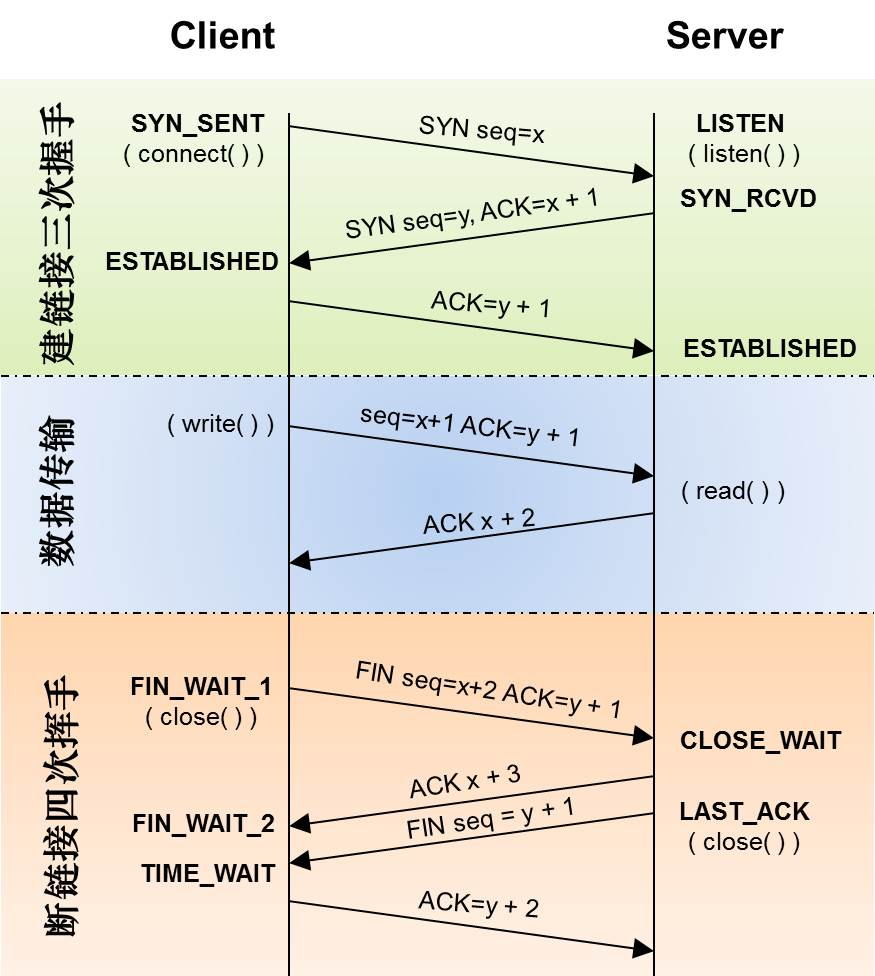
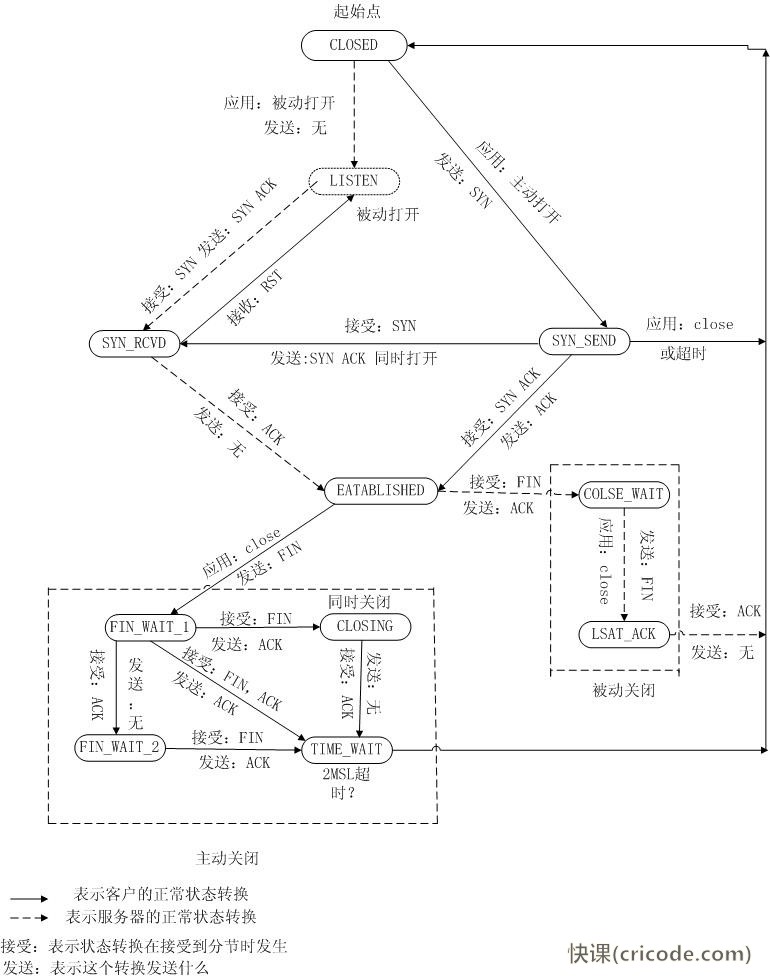
如果此时port A 等于 port B, 那么此时实际上是没有服务器在port B 上监听的,不然的话,client不会分配到port B。在这种情况下,client发送的SYN包会来到端口B上,此时由于client已经打开了端口B,系统会以为端口B上有服务器在监听,那么就直接接收SYN包,并发给client。这种情况其实就是client和server同时发起连接,client此时的状态为SYN_RECEIVE,按照TCP的三次握手,client会跟自己建立起了连接。此时就出现了自连接。
void EventLoop::quit() { quit_ = true; // There is a chance that loop() just executes while(!quit_) and exits, // then EventLoop destructs, then we are accessing an invalid object. // Can be fixed using mutex_ in both places. if (!isInLoopThread()) { wakeup(); } }
(1) The gettid() system call first appeared on Linux in kernel 2.4.11. (2) gettid() returns the thread ID of the current process. This is equal to the process ID (as returned by getpid(2)), unless the process is part of a thread group (created by specifying the CLONE_THREAD flag to the clone(2) system call). All processes in the same thread group have the same PID, but each one has a unique TID. (3) gettid() is Linux specific and should not be used in programs that are intended to be portable. (如果考虑移植性,不应该使用此接口)
1 2 3 4 5
#include<sys/syscall.h> #define gettidv1() syscall(__NR_gettid) #define gettidv2() syscall(SYS_gettid) printf("The ID of this thread is: %ld\n", (longint)gettidv1());// 最新的方式 printf("The ID of this thread is: %ld\n", (longint)gettidv2());// 传统方式
voidbuildTree(){ queue <int> q; int p0 = 1; while (ath[p0][0]) p0 = ath[p0][0]; d[p0] = 1; q. push(p0); while (!q. empty()) { int p = q. front(); q. pop(); for (int i = 1; i < maxl; ++ i) ath[p][i] = ath[ath[p][i - 1]][i - 1]; for (vector <int> :: iterator i = e[p]. begin(); i != e[p]. end(); ++ i) { q. push(*i); d[*i] = d[p] + 1; } } }
intLCA(int p, int q){ if (d[p] < d[q]) swap(p, q); for (int i = maxl - 1; i >= 0; -- i) if (d[ath[p][i]] >= d[q]) p = ath[p][i]; if (p == q) return p; for (int i = maxl - 1; i >= 0; -- i) if (ath[p][i] ^ ath[q][i]) p = ath[p][i], q = ath[q][i]; return ath[p][0]; }
intmain(){ cin. sync_with_stdio(0); cin >> n; tn = 0; while (n --) { string a, b; cin >> a >> b; int na = getNum(a), nb = getNum(b); ath[nb][0] = na; e[na]. push_back(nb); } buildTree(); cin >> m; while (m --) { string a, b; cin >> a >> b; int na = getNum(a), nb = getNum(b); cout << name[LCA(na, nb)] << endl; } }
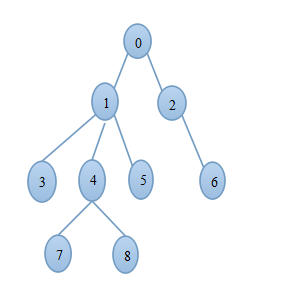
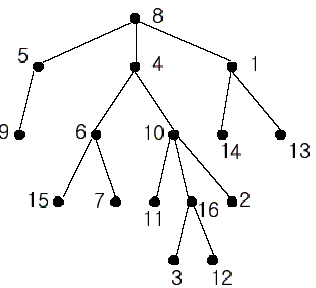
A rooted tree is a well-known data structure in computer science and engineering. An example is shown below:
In the figure, each node is labeled with an integer from {1, 2,…,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
The input consists of T test cases. The number of test cases (T) is given in the first line of the input file. Each test case starts with a line containing an integer N , the number of nodes in a tree, 2<=N<=10,000. The nodes are labeled with integers 1, 2,…, N. Each of the next N -1 lines contains a pair of integers that represent an edge –the first integer is the parent node of the second integer. Note that a tree with N nodes has exactly N - 1 edges. The last line of each test case contains two distinct integers whose nearest common ancestor is to be computed. Output
Print exactly one line for each test case. The line should contain the integer that is the nearest common ancestor.
After World War X, a lot of cities have been seriously damaged, and we need to rebuild those cities. However, some materials needed can only be produced in certain places. So we need to transport these materials from city to city. For most of roads had been totally destroyed during the war, there might be no path between two cities, no circle exists as well. Now, your task comes. After giving you the condition of the roads, we want to know if there exists a path between any two cities. If the answer is yes, output the shortest path between them.
Input
Input consists of multiple problem instances.For each instance, first line contains three integers n, m and c, 2<=n<=10000, 0<=m<10000, 1<=c<=1000000. n represents the number of cities numbered from 1 to n. Following m lines, each line has three integers i, j and k, represent a road between city i and city j, with length k. Last c lines, two integers i, j each line, indicates a query of city i and city j.
Output
For each problem instance, one line for each query. If no path between two cities, output “Not connected”, otherwise output the length of the shortest path between them.
#define lchild rt << 1, l, m #define rchild rt << 1 | 1, m + 1, r voidupdate(int p, int delta, int rt = 1, int l = 1, int r = N){ if (l == r) { tree[rt] += delta; return; } int m = (l + r) >> 1; if (p <= m) update(p, delta, lchild); else update(p, delta, rchild); push_up(rt); }
成段更新,需要用到lazy来提高效率,下面代码是区间和的情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
#define lchild rt << 1, l, m #define rchild rt << 1 | 1, m + 1, r voidupdate(int L, int R, int delta, int rt = 1, int l = 1, int r = N){ if (L <= l && r <= R) { tree[rt] += delta * (r - l + 1); lazy[rt] += delta; return; } if (lazy[rt]) push_down(rt, r - l + 1); int m = (l + r) >> 1; if (L <= m) update(L, R, delta, lchild); if (R > m) update(L, R, delta, rchild); push_up(rt); }
query
查询也是要根据具体功能来实现,下面是查询区间和的代码
1 2 3 4 5 6 7 8 9 10
#define lchild rt << 1, l, m #define rchild rt << 1 | 1, m + 1, r int query(int L, int R, int rt = 1, int l = 1, int r = N) { if (L <= l && r <= R) return tree[rt]; if (lazy[rt]) push_down(rt, r - l + 1); int m = (l + r) >> 1, ret = 0; if (L <= m) ret += query(L, R, lchild); if (R > m) ret += query(L, R, rchild); returnret; }
The inversion number of a given number sequence a1, a2, …, an is the number of pairs (ai, aj) that satisfy i < j and ai > aj.
For a given sequence of numbers a1, a2, …, an, if we move the first m >= 0 numbers to the end of the seqence, we will obtain another sequence. There are totally n such sequences as the following:
a1, a2, …, an-1, an (where m = 0 - the initial seqence) a2, a3, …, an, a1 (where m = 1) a3, a4, …, an, a1, a2 (where m = 2) … an, a1, a2, …, an-1 (where m = n-1)
You are asked to write a program to find the minimum inversion number out of the above sequences.
Input
The input consists of a number of test cases. Each case consists of two lines: the first line contains a positive integer n (n <= 5000); the next line contains a permutation of the n integers from 0 to n-1.
Output
For each case, output the minimum inversion number on a single line.
#define lson l , m , rt << 1 #define rson m + 1 , r , rt << 1 | 1 constint maxn = 5555; int sum[maxn<<2]; voidPushUP(int rt){ sum[rt] = sum[rt<<1] + sum[rt<<1|1]; } voidbuild(int l,int r,int rt){ sum[rt] = 0; if (l == r) return ; int m = (l + r) >> 1; build(lson); build(rson); } voidupdate(int p,int l,int r,int rt){ if (l == r) { sum[rt] ++; return ; } int m = (l + r) >> 1; if (p <= m) update(p , lson); else update(p , rson); PushUP(rt); } intquery(int L,int R,int l,int r,int rt){ if (L <= l && r <= R) { return sum[rt]; } int m = (l + r) >> 1; int ret = 0; if (L <= m) ret += query(L , R , lson); if (R > m) ret += query(L , R , rson); return ret; } int x[maxn]; intmain(){ int n; while (~scanf("%d",&n)) { build(0 , n - 1 , 1); int sum = 0; for (int i = 0 ; i < n ; i ++) { scanf("%d",&x[i]); sum += query(x[i] , n - 1 , 0 , n - 1 , 1); update(x[i] , 0 , n - 1 , 1); } int ret = sum; for (int i = 0 ; i < n ; i ++) { sum += n - x[i] - x[i] - 1; ret = min(ret , sum); } printf("%d\n",ret); } return0; }
At the entrance to the university, there is a huge rectangular billboard of size h*w (h is its height and w is its width). The board is the place where all possible announcements are posted: nearest programming competitions, changes in the dining room menu, and other important information.
On September 1, the billboard was empty. One by one, the announcements started being put on the billboard.
Each announcement is a stripe of paper of unit height. More specifically, the i-th announcement is a rectangle of size 1 * wi.
When someone puts a new announcement on the billboard, she would always choose the topmost possible position for the announcement. Among all possible topmost positions she would always choose the leftmost one.
If there is no valid location for a new announcement, it is not put on the billboard (that’s why some programming contests have no participants from this university).
Given the sizes of the billboard and the announcements, your task is to find the numbers of rows in which the announcements are placed.
Input
There are multiple cases (no more than 40 cases).
The first line of the input file contains three integer numbers, h, w, and n (1 <= h,w <= 10^9; 1 <= n <= 200,000) - the dimensions of the billboard and the number of announcements.
Each of the next n lines contains an integer number wi (1 <= wi <= 10^9) - the width of i-th announcement.
Output
For each announcement (in the order they are given in the input file) output one number - the number of the row in which this announcement is placed. Rows are numbered from 1 to h, starting with the top row. If an announcement can’t be put on the billboard, output “-1” for this announcement.
In the game of DotA, Pudge’s meat hook is actually the most horrible thing for most of the heroes. The hook is made up of several consecutive metallic sticks which are of the same length.
Now Pudge wants to do some operations on the hook.
Let us number the consecutive metallic sticks of the hook from 1 to N. For each operation, Pudge can change the consecutive metallic sticks, numbered from X to Y, into cupreous sticks, silver sticks or golden sticks. The total value of the hook is calculated as the sum of values of N metallic sticks. More precisely, the value for each kind of stick is calculated as follows:
For each cupreous stick, the value is 1. For each silver stick, the value is 2. For each golden stick, the value is 3.
Pudge wants to know the total value of the hook after performing the operations. You may consider the original hook is made up of cupreous sticks.
Input
The input consists of several test cases. The first line of the input is the number of the cases. There are no more than 10 cases. For each case, the first line contains an integer N, 1<=N<=100,000, which is the number of the sticks of Pudge’s meat hook and the second line contains an integer Q, 0<=Q<=100,000, which is the number of the operations. Next Q lines, each line contains three integers X, Y, 1<=X<=Y<=N, Z, 1<=Z<=3, which defines an operation: change the sticks numbered from X to Y into the metal kind Z, where Z=1 represents the cupreous kind, Z=2 represents the silver kind and Z=3 represents the golden kind.
Output
For each case, print a number in a line representing the total value of the hook after the operations. Use the format in the example.
#define lson l , m , rt << 1 #define rson m + 1 , r , rt << 1 | 1 constint maxn = 111111; int h , w , n; int col[maxn<<2]; int sum[maxn<<2]; voidPushUp(int rt){ sum[rt] = sum[rt<<1] + sum[rt<<1|1]; } voidPushDown(int rt,int m){ if (col[rt]) { col[rt<<1] = col[rt<<1|1] = col[rt]; sum[rt<<1] = (m - (m >> 1)) * col[rt]; sum[rt<<1|1] = (m >> 1) * col[rt]; col[rt] = 0; } } voidbuild(int l,int r,int rt){ col[rt] = 0; sum[rt] = 1; if (l == r) return ; int m = (l + r) >> 1; build(lson); build(rson); PushUp(rt); } voidupdate(int L,int R,int c,int l,int r,int rt){ if (L <= l && r <= R) { col[rt] = c; sum[rt] = c * (r - l + 1); return ; } PushDown(rt , r - l + 1); int m = (l + r) >> 1; if (L <= m) update(L , R , c , lson); if (R > m) update(L , R , c , rson); PushUp(rt); } intmain(){ int T , n , m; scanf("%d",&T); for (int cas = 1 ; cas <= T ; cas ++) { scanf("%d%d",&n,&m); build(1 , n , 1); while (m --) { int a , b , c; scanf("%d%d%d",&a,&b,&c); update(a , b , c , 1 , n , 1); } printf("Case %d: The total value of the hook is %d.\n",cas , sum[1]); } return0; }
You have N integers, A1, A2, … , AN. You need to deal with two kinds of operations. One type of operation is to add some given number to each number in a given interval. The other is to ask for the sum of numbers in a given interval.
Input
The first line contains two numbers N and Q. 1 ≤ N,Q ≤ 100000. The second line contains N numbers, the initial values of A1, A2, … , AN. -1000000000 ≤ Ai ≤ 1000000000. Each of the next Q lines represents an operation. “C a b c” means adding c to each of Aa, Aa+1, … , Ab. -10000 ≤ c ≤ 10000. “Q a b” means querying the sum of Aa, Aa+1, … , Ab.
Output
You need to answer all Q commands in order. One answer in a line.
//加锁的实现函数,成功返回null,不成功返回锁的存活时间,-1表示锁永不超时 private Long tryLockInner() { //保存锁的状态: 客户端UUID+线程ID来唯一标识某一JVM实例的某一线程 final LockValue currentLock = new LockValue(id, Thread.currentThread().getId());
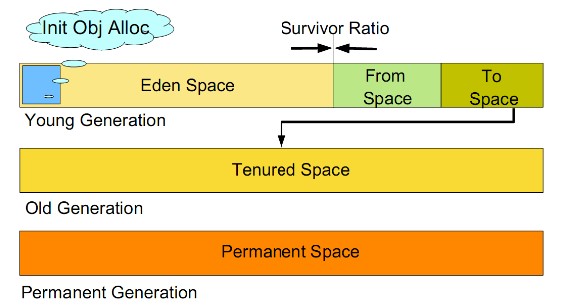
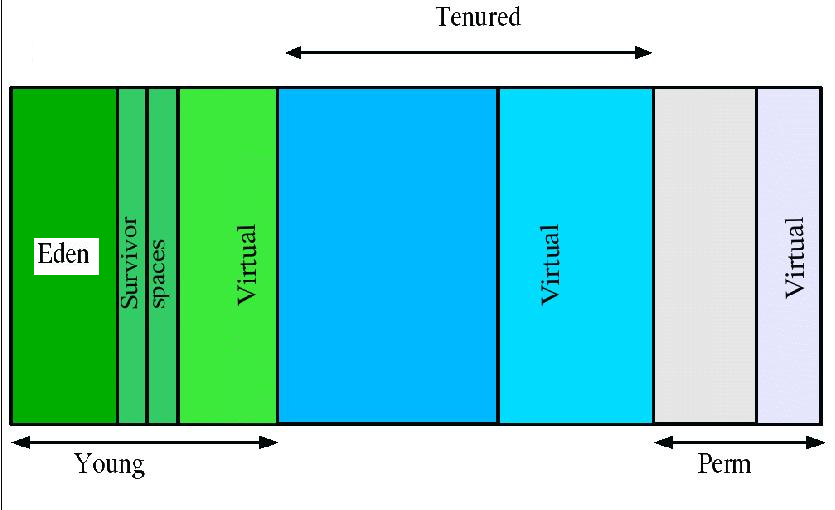
JVM中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限 制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。在 Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。 典型设置:
Class cls = Class.forName("chb.test.reflect.Student"); Method m = cls.getDeclaredMethod("hi",newClass[]{int.class,String.class}); m.invoke(cls.newInstance(),20,"chb");
//static方法调用时,不必得到对象 Class cls = Class.forName("chb.test.reflect.Student"); Method staticMethod = cls.getDeclaredMethod("hi",int.class,String.class); staticMethod.invoke(cls,20,"chb");//这里不需要newInstance
//运行错误输出 java.lang.reflect.InvocationTargetException at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25) at java.lang.reflect.Method.invoke(Method.java:597) at classloader.ClassIdentity.testClassIdentity(ClassIdentity.java:26) at classloader.ClassIdentity.main(ClassIdentity.java:9) Caused by: java.lang.ClassCastException: com.example.Sample cannot be cast to com.example.Sample at com.example.Sample.setSample(Sample.java:7) ... 6 more
但是同步一个方法可能造成程序执行效率降低100倍,而且其实在getInstance函数中,并不是整一个方法都属于资源竞争的范围,只有uniqueInstance = new Singleton()语句才是,而且只有在单例对象第一次初始化的时候才会执行该语句,其余的都不会进入到该语句中,所以直接对整一个方法进行同步有点浪费。 可以双重检查加锁,在getInstance函数中减少同步
public class PizzaStore{ public Pizza orderPizza(Stringtype){ Pizza p; if("aa".equals(type)) p = new AAPizaa(); //AAPizza为Pizaa的子类 if("bb".equals(type)) p = BBPizaa(); //BBPizza为Pizaa的子类 if... ... ... return p;
//实例化的工作被抽离出来 public class SimplePizzaFactory{ public SimplePizzaFactory(){}; public Pizza createPizza(Stringtype){ if("aa".equals(type)) reutrn new AAPizza(); //AAPizza为Pizza的子类 if("bb".equals(type)) return BBPizza(); //BBPizza为Pizza的子类 if... ... } } public class PizzaStore{ SimplePizzaFactory spf; public PizzaStore(SimplePizzaFactory spf){ this.spf = spf; } public Pizza orderPizza(Stringtype){ Pizza p; p = spf.createPizza(type); ... ... return p;
public abstractclassPizzaStore(){ abstractPizza createPizza(Stringtype);//工厂方法,具体pizza类的实例化由派生类来实现 public Pizza orderPizza(Stringtype){ Pizza p; p = createPizza(type);
} }
//具体的对象实例化由派生类决定 public classAAPizzaStore() extendsPizzaStore{ Pizza createPizza(Stringtype){ System.out.println("I'm AAPizzaStore"); if("aa".equals(type)) reutrn newAA1Pizza(); //AA1Pizza为Pizza的子类 if("bb".equals(type)) returnAA2Pizza(); //AA2Pizza为Pizza的子类 if ... ... }
}
public classBBPizzaStore() extendsPizzaStore{ Pizza createPizza(Stringtype){ System.out.println("I'm BBPizzaStore"); if("aa".equals(type)) reutrn newBB1Pizza(); //BB1Pizza为Pizza的子类 if("bb".equals(type)) returnBB2Pizza(); //BB2Pizza为Pizza的子类 if ... ... }
auto i = 42; auto a = 3.14; auto p = new Ptr(); auto i=0,&r=i; auto a=r;//a为int,因为r是i的别名,i为int。 vector<int> v; auto b = v.begin(); std::map<std::string, std::vector<int>> map; for(auto it = begin(map); it != end(map); ++it) {};
decltype(f()) sum=x; //sum的类型就是f返回值的类型, 但是这里不执行函数f() auto x= 12; auto y = 13; typedefdecltype(x*y) Type; decltype(x*y) xy; //xy的类型为int //decltype声明函数指针的时,关键是要记住decltype返回的是一个函数的类型的,因此要加上*声明符才能构成完整的函数指针的类型 intf(int a, int b){return a+b;}; decltype(f)* k = f; //直接decltype(f) k = f 是不可以的 k(1, 2);
int k=9; decltype(*p) c=k; //c为int&,必须初始化 decltype((i)) d = k; //d为int&,必须初始化 decltype(++i) e = k //e为int&, 必须初始化 decltype(i++) f; //f 为int类型 tecltype(f=k) g //g为int&类型,必须初始化
onst int ci=i,&cr=i; auto a=ci; //a为int(忽略顶层const) auto b=cr; //b为int(忽略顶层const,cr是引用) auto c=&i; //c为int * auto d=&ci; //d是pointer to const int(&ci为底层const) //要声明顶层const,前面要加上const关键字;要声明引用要加上&标识符 constauto f=ci; //ci的推演类型是int,f是const int auto &g=ci;// g是一个绑定到ci的引用
对于decltype,其对const和应用的处理如下
1 2 3 4 5 6
constint ci=0; decltype(ci) x=0; //x的类型是const int int i=42,*p=&i,&r=i; decltype(r+0) b; //b为int constint &cj=ci; decltype(cj) y=x; //y的类型是const int&,y绑定到x上
template<class T> class A { public: staticconstexpr T min()throw(){ return T(); } staticconstexpr T max()throw(){ return T(); } staticconstexpr T lowest()throw(){ return T(); } ...
而在C++11中,则使用noexcept来替换throw()。
1 2 3 4 5 6
template<class T> class A { public: staticconstexpr T min()noexcept{ return T(); } staticconstexpr T max()noexcept{ return T(); } staticconstexpr T lowest()noexcept{ return T(); } ...
struct Point { int x,y; constexpr Point(int xx, int yy) : x(xx), y(yy) { } }; constexpr Point origo(0,0); constexpr int z = origo.x; constexpr Point a[] = {Point(0,0), Point(1,1), Point(2,2) }; constexpr int x = a[1].x; // x becomes 1
template <typename T1, typename T2> auto add(T1 t1, T2 t2) -> decltype(t1 + t2) { static_assert(std::is_integral<T1>::value, "Type T1 must be integral"); static_assert(std::is_integral<T2>::value, "Type T2 must be integral");
return t1 + t2; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14
error C2338: Type T2 must be integral see reference tofunction template instantiation 'T2 add<int,double>(T1,T2)' being compiled with [ T2=double, T1=int ] error C2338: Type T1 must be integral see reference tofunction template instantiation 'T1 add<const char*,int>(T1,T2)' being compiled with [ T1=constchar *, T2=int ]
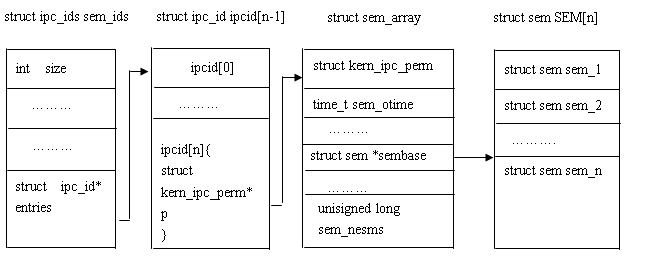
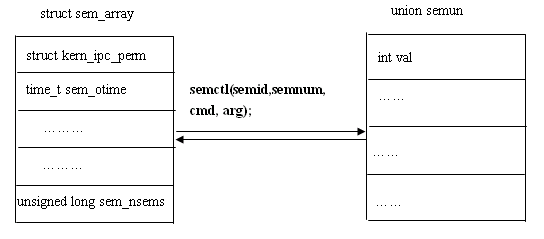
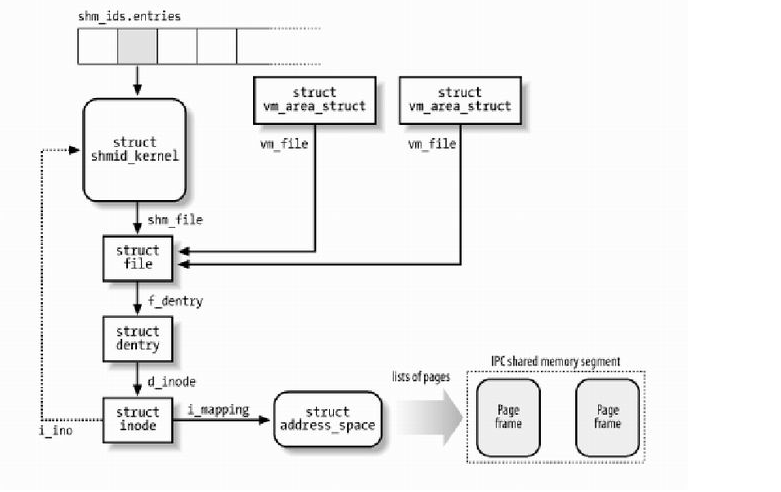
/*系统中的每个信号灯集对应一个sem_array 结构 */ struct sem_array { struct kern_ipc_perm sem_perm; /* permissions .. see ipc.h */ time_t sem_otime; /* last semop time */ time_t sem_ctime; /* last change time */ struct sem *sem_base; /* ptr to first semaphore in array */ struct sem_queue *sem_pending; /* pending operations to be processed */ struct sem_queue **sem_pending_last; /* last pending operation */ struct sem_undo *undo; /* undo requests on this array */ unsigned long sem_nsems; /* no. of semaphores in array */ };
其中,sem_queue结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* 系统中每个因为信号灯而睡眠的进程,都对应一个sem_queue结构*/ struct sem_queue { struct sem_queue * next; /* next entry in the queue */ struct sem_queue ** prev; /* previous entry in the queue, *(q->prev) == q */ struct task_struct* sleeper; /* this process */ struct sem_undo * undo; /* undo structure */ int pid; /* process id of requesting process */ int status; /* completion status of operation */ struct sem_array * sma; /* semaphore array for operations */ int id; /* internal sem id */ struct sembuf * sops; /* array of pending operations */ int nsops; /* number of operations */ int alter; /* operation will alter semaphore */ };
union semun { int val; /* value for SETVAL */ struct semid_ds *buf; /* buffer for IPC_STAT & IPC_SET */ unsignedshort *array; /* array for GETALL & SETALL */ struct seminfo *__buf; /* buffer for IPC_INFO *///test!! void *__pad; }; struct seminfo { int semmap; int semmni; int semmns; int semmnu; int semmsl; int semopm; int semume; int semusz; int semvmx; int semaem; };
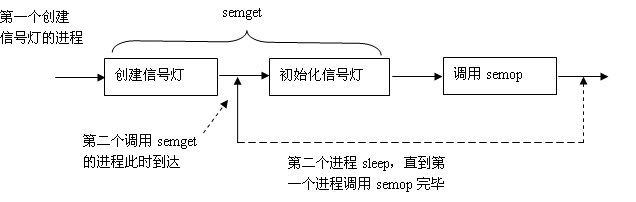
#include<linux/sem.h> #include<stdio.h> #include<errno.h> #define SEM_PATH "/unix/my_sem" #define max_tries 3 int semid; main() { int flag1,flag2,key,i,init_ok,tmperrno; struct semid_ds sem_info; struct seminfo sem_info2; union semun arg; //union semun: 请参考附录2 struct sembuf askfor_res, free_res; flag1=IPC_CREAT|IPC_EXCL|00666; flag2=IPC_CREAT|00666; key=ftok(SEM_PATH,'a'); //error handling for ftok here; init_ok=0; semid=semget(key,1,flag1); //create a semaphore set that only includes one semphore. if(semid<0) { tmperrno=errno; perror("semget"); if(tmperrno==EEXIST) //errno is undefined after a successful library call( including perror call) //so it is saved in tmperrno. { semid=semget(key,1,flag2); //flag2 只包含了IPC_CREAT标志, 参数nsems(这里为1)必须与原来的信号灯数目一致 arg.buf=&sem_info; for(i=0; i<max_tries; i++) { if(semctl(semid, 0, IPC_STAT, arg)==-1) { perror("semctl error"); i=max_tries;} else { if(arg.buf->sem_otime!=0){ i=max_tries; init_ok=1;} else sleep(1); } } if(!init_ok) // do some initializing, here we assume that the first process that creates the sem // will finish initialize the sem and run semop in max_tries*1 seconds. else it will // not run semop any more. { arg.val=1; if(semctl(semid,0,SETVAL,arg)==-1) perror("semctl setval error"); } } else {perror("semget error, process exit"); exit(); } } else//semid>=0; do some initializing { arg.val=1; if(semctl(semid,0,SETVAL,arg)==-1) perror("semctl setval error"); } //get some information about the semaphore and the limit of semaphore in redhat8.0 arg.buf=&sem_info; if(semctl(semid, 0, IPC_STAT, arg)==-1) perror("semctl IPC STAT"); printf("owner's uid is %d\n", arg.buf->sem_perm.uid); printf("owner's gid is %d\n", arg.buf->sem_perm.gid); printf("creater's uid is %d\n", arg.buf->sem_perm.cuid); printf("creater's gid is %d\n", arg.buf->sem_perm.cgid); arg.__buf=&sem_info2; if(semctl(semid,0,IPC_INFO,arg)==-1) perror("semctl IPC_INFO"); printf("the number of entries in semaphore map is %d \n", arg.__buf->semmap); printf("max number of semaphore identifiers is %d \n", arg.__buf->semmni); printf("mas number of semaphores in system is %d \n", arg.__buf->semmns); printf("the number of undo structures system wide is %d \n", arg.__buf->semmnu); printf("max number of semaphores per semid is %d \n", arg.__buf->semmsl); printf("max number of ops per semop call is %d \n", arg.__buf->semopm); printf("max number of undo entries per process is %d \n", arg.__buf->semume); printf("the sizeof of struct sem_undo is %d \n", arg.__buf->semusz); printf("the maximum semaphore value is %d \n", arg.__buf->semvmx);
//now ask for available resource: askfor_res.sem_num=0; askfor_res.sem_op=-1; askfor_res.sem_flg=SEM_UNDO;
if(semop(semid,&askfor_res,1)==-1)//ask for resource perror("semop error");
sleep(3); //do some handling on the sharing resource here, just sleep on it 3 seconds printf("now free the resource\n");
//now free resource free_res.sem_num=0; free_res.sem_op=1; free_res.sem_flg=SEM_UNDO; if(semop(semid,&free_res,1)==-1)//free the resource. if(errno==EIDRM) printf("the semaphore set was removed\n"); //you can comment out the codes below to compile a different version: if(semctl(semid, 0, IPC_RMID)==-1) perror("semctl IPC_RMID"); elseprintf("remove sem ok\n"); }
owner's uid is 0 owner's gid is0 creater's uid is 0 creater's gid is0 the number of entries in semaphore map is32000 max number of semaphore identifiers is128 mas number of semaphores in system is32000 the number of undo structures system wide is32000 max number of semaphores per semid is250 max number of ops per semop call is32 max number of undo entries per process is32 the sizeof of struct sem_undo is20 the maximum semaphore value is32767 now free the resource remove sem ok
int ipc(unsigned intcall, intfirst, int second, int third, void * ptr, long fifth); 第一个参数指明对IPC对象的操作方式,对消息队列而言共有四种操作:MSGSND、MSGRCV、MSGGET以及MSGCTL,分别代表向消息队列发送消息、从消息队列读取消息、打开或创建消息队列、控制消息队列;first参数代表唯一的IPC对象;下面将介绍四种操作.
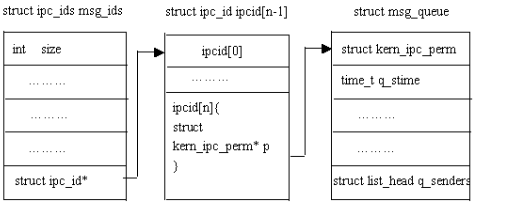
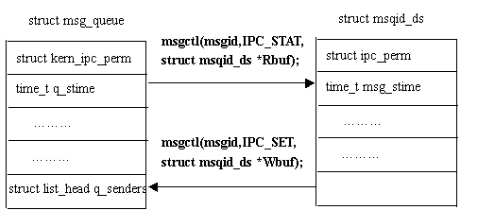
struct msg_queue { struct kern_ipc_perm q_perm; time_t q_stime; /* last msgsnd time */ time_t q_rtime; /* last msgrcv time */ time_t q_ctime; /* last change time */ unsignedlong q_cbytes; /* current number of bytes on queue */ unsignedlong q_qnum; /* number of messages in queue */ unsignedlong q_qbytes; /* max number of bytes on queue */ pid_t q_lspid; /* pid of last msgsnd */ pid_t q_lrpid; /* last receive pid */ struct list_head q_messages; struct list_head q_receivers; struct list_head q_senders; };
结构msqid_ds用来设置或返回消息队列的信息,存在于用户空间;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
struct msqid_ds { struct ipc_perm msg_perm; struct msg *msg_first; /* first message on queue,unused */ struct msg *msg_last; /* last message in queue,unused */ __kernel_time_t msg_stime; /* last msgsnd time */ __kernel_time_t msg_rtime; /* last msgrcv time */ __kernel_time_t msg_ctime; /* last change time */ unsignedlong msg_lcbytes; /* Reuse junk fields for 32 bit */ unsignedlong msg_lqbytes; /* ditto */ unsignedshort msg_cbytes; /* current number of bytes on queue */ unsignedshort msg_qnum; /* number of messages in queue */ unsignedshort msg_qbytes; /* max number of bytes on queue */ __kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */ __kernel_ipc_pid_t msg_lrpid; /* last receive pid */ };
current number of bytes on queue is 0 number of messages in queue is 0 max number of bytes on queue is 16384 pid of last msgsnd is 0 pid of last msgrcv is 0 last msgsnd time is Thu Jan 1 08:00:00 1970 last msgrcv time is Thu Jan 1 08:00:00 1970 last changetimeis Sun Dec2918:28:202002 msg uid is0 msg gid is0 //上面刚刚创建一个新消息队列时的输出 currentnumberofbyteson queue is1 numberof messages in queue is1 maxnumberofbyteson queue is16384 pid oflast msgsnd is2510 pid oflast msgrcv is0 last msgsnd timeis Sun Dec2918:28:212002 last msgrcv timeis Thu Jan 108:00:001970 lastchangetimeis Sun Dec2918:28:202002 msg uid is0 msg gid is0 readfrom msg queue 1bytes //实际读出的字节数 currentnumberofbyteson queue is0 numberof messages in queue is0 maxnumberofbyteson queue is16384 //每个消息队列最大容量(字节数) pid oflast msgsnd is2510 pid oflast msgrcv is2510 last msgsnd timeis Sun Dec2918:28:212002 last msgrcv timeis Sun Dec2918:28:222002 lastchangetimeis Sun Dec2918:28:202002 msg uid is0 msg gid is0 currentnumberofbyteson queue is0 numberof messages in queue is0 maxnumberofbyteson queue is16388 //可看出超级用户可修改消息队列最大容量 pid oflast msgsnd is2510 pid oflast msgrcv is2510 //对操作消息队列进程的跟踪 last msgsnd timeis Sun Dec2918:28:212002 last msgrcv timeis Sun Dec2918:28:222002 lastchangetimeis Sun Dec2918:28:232002 //msgctl()调用对msg_ctime有影响 msg uid is8 msg gid is8
/*-------------map_normalfile1.c-----------*/ #include<sys/mman.h> #include<sys/types.h> #include<fcntl.h> #include<unistd.h> typedefstruct{ char name[4]; int age; }people; main(int argc, char** argv) // map a normal file as shared mem: { int fd,i; people *p_map; char temp;
在map_normalfile1输出initialize over 之后,输出umap ok之前,在另一个终端上运行map_normalfile2 /tmp/test_shm,将会产生如下输出(为了节省空间,输出结果为稍作整理后的结果):
1 2
name: b age 20; name: c age 21; name: d age 22; name: e age 23; name: f age 24; name: g age 25; name: h age 26; name: I age 27; name: j age 28; name: k age 29;
name: b age 20; name: c age 21; name: d age 22; name: e age 23; name: f age 24; name: age 0; name: age 0; name: age 0; name: age 0; name: age 0;
从程序的运行结果中可以得出的结论
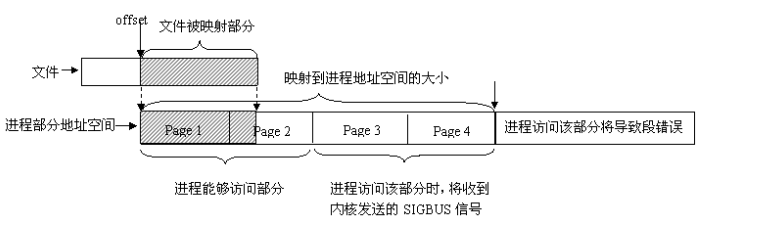
1、最终被映射文件的内容的长度不会超过文件本身的初始大小,即映射不能改变文件的大小;
2、可以用于进程通信的有效地址空间大小大体上受限于被映射文件的大小,但不完全受限于文件大小。打开文件被截短为5个people结构大小,而在map_normalfile1中初始化了10个people数据结构,在恰当时候(map_normalfile1输出initialize over 之后,输出umap ok之前)调用map_normalfile2会发现map_normalfile2将输出全部10个people结构的值,后面将给出详细讨论。 注:在linux中,内存的保护是以页为基本单位的,即使被映射文件只有一个字节大小,内核也会为映射分配一个页面大小的内存。当被映射文件小于一个页面大小时,进程可以对从mmap()返回地址开始的一个页面大小进行访问,而不会出错;但是,如果对一个页面以外的地址空间进行访问,则导致错误发生,后面将进一步描述。因此,可用于进程间通信的有效地址空间大小不会超过文件大小及一个页面大小的和。
name: b age 20; name: c age 21; name: d age 22; name: e age 23; name: f age 24; name: g age 25; name: h age 26; name: I age 27; name: j age 28; name: k age 29;
当管道的写端存在时,如果请求的字节数目大于PIPE_BUF,则返回管道中现有的数据字节数,如果请求的字节数目不大于PIPE_BUF,则返回管道中现有数据字节数(此时,管道中数据量小于请求的数据量);或者返回请求的字节数(此时,管道中数据量不小于请求的数据量)。注:(PIPE_BUF在include/linux/limits.h中定义,不同的内核版本可能会有所不同。Posix.1要求PIPE_BUF至少为512字节,red hat 7.2中为4096)。
if((pid=fork())==0) { printf("\n"); close(pipe_fd[1]); sleep(3);//确保父进程关闭写端 r_num=read(pipe_fd[0],r_buf,100); printf( "read num is %d the data read from the pipe is %d\n",r_num,atoi(r_buf));
close(pipe_fd[0]); exit(); } else if(pid>0) { close(pipe_fd[0]);//read strcpy(w_buf,"111"); if(write(pipe_fd[1],w_buf,4)!=-1) printf("parent write over\n"); close(pipe_fd[1]);//write printf("parent close fd[1] over\n"); sleep(10); } } /************************************************** * 程序输出结果: * parent write over * parent close fd[1] over * read num is 4 the data read from the pipe is 111 * 附加结论: * 管道写端关闭后,写入的数据将一直存在,直到读出为止. ****************************************************/
exit(); } elseif(pid>0) { close(pipe_fd[0]);//write memset(r_buf,0,sizeof(r_buf)); if((writenum=write(pipe_fd[1],w_buf,1024))==-1) printf("write to pipe error\n"); else printf("the bytes write to pipe is %d \n", writenum); writenum=write(pipe_fd[1],w_buf,4096); close(pipe_fd[1]); } } 输出结果: the bytes write to pipe 1000 the bytes write to pipe 1000//注意,此行输出说明了写入的非原子性 the bytes write to pipe 1000 the bytes write to pipe 1000 the bytes write to pipe 1000 the bytes write to pipe 120//注意,此行输出说明了写入的非原子性 the bytes write to pipe 0 the bytes write to pipe 0 ......
管道应用的一个重大限制是它没有名字,因此,只能用于具有亲缘关系的进程间通信,在有名管道(named pipe或FIFO)提出后,该限制得到了克服。FIFO不同于管道之处在于它提供一个路径名与之关联,以FIFO的文件形式存在于文件系统中。这样,即使与FIFO的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过FIFO相互通信(能够访问该路径的进程以及FIFO的创建进程之间),因此,通过FIFO不相关的进程也能交换数据。值得注意的是,FIFO严格遵循先进先出(first in first out),对管道及FIFO的读总是从开始处返回数据,对它们的写则把数据添加到末尾。它们不支持诸如lseek()等文件定位操作。
} inthandle_client(char* arg) { int ret; ret=w_open(arg); switch(ret) { case0: { printf("open %s error\n",arg); printf("no process has the fifo open for reading\n"); return -1; } case -1: { printf("something wrong with open the fifo except for ENXIO"); return -1; } case1: { printf("open server ok\n"); return1; } default: { printf("w_no_r return ----\n"); return0; } } unlink(FIFO_SERVER); } intw_open(char*arg) //0 open error for no reading //-1 open error for other reasons //1 open ok { if(open(arg,O_WRONLY|O_NONBLOCK,0)==-1) { if(errno==ENXIO) { return0; } else return -1; } return1;
/* Send to clients listening for that channel */ // 取出包含所有订阅频道 channel 的客户端的链表 // 并将消息发送给它们 de = dictFind(server.pubsub_channels,channel); if (de) { list *list = dictGetVal(de); listNode *ln; listIter li;
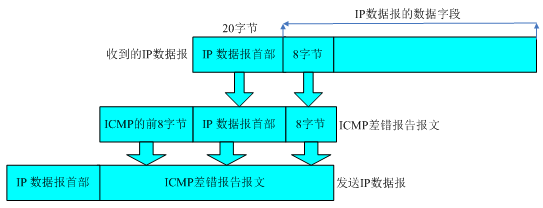
ICMP 经常被认为是 IP 层的一个组成部分,它传递差错报文以及其他需要注意的信息。ICMP 报文通常被 IP 层或更高层协议(TCP 或 UDP)使用。ICMP 报文是在 IP 数据报内部传输的。IP 协议是不可靠协议,不能保证 IP 数据报能够成功的到达目的主机,无法进行差错控制,而 ICMP 协议能够协助 IP 协议完成这些功能。下面是 ICMP 报文的数据结构:
类型:一个 8 位类型字段,表示 ICMP 数据包类型;
代码:一个 8 位代码域,表示指定类型中的一个功能,如果一个类型中只有一种功能,代码域置为 0;
检验和:数据包中 ICMP 部分上的一个 16 位检验和;
以下针对 ICMP 差错报文的类型进行分析:
1、ICMP 目标不可达消息:IP 路由器无法将 IP 数据报发送给目的地址时,会给发送端主机返回一个目标不可达 ICMP 消息,并在这个消息中显示不可达的具体原因。
port restricted cone类型在restricted cone类型的基础上增加了port的限制,必须又内网的机器访问外网机器的某个端口,该外网机器的对应端口发出的数据包才可以通过NAT。NAT维持的映射关系如下: {对端外网ip:对端外网port:内网ip:内网port}—->{公网ip:公网port},同一个机器的特定端口才可以通过该映射。
classB { UINT valueB; //error C2146: syntax error : missing ';' before identifier 'valueB' //error C4430: missing type specifier - int assumed. Note: C++ does not support default-int };
extern 用来声明一个外部变量或是函数,表示该变量已经在其他的地方定义了,这里只是做一个引用而已,不会产生新的变量。对于extern修饰的变量,编译器会在所在的文件先看看有没有对该变量的定义,有的话,直接应用,没有的话再到其他的文件里面进行查找。由于变量已经在其他的地方定义了,所以extern int a = 10;这种写法是不对的,会造成重定义错误!
寄存器变量,请求编译器将这个变量保存在CPU的寄存器中,从而加快程序的运行。系统的寄存器是有限制的,声明变量时如:register int i.这种存储类型可以用于频繁使用的变量。实际上现在一般的编译器都忽略auto和register申明,现在的编译器自己能够区分最好将那些变量放置在寄存器中,那些放置在堆栈中;甚至于将一些变量有时存放在堆栈,有时存放在寄存器中。
In computer operating systems terminology, a sleeping process can either be interruptible (woken via signals) or uninterruptible (woken explicitly). An uninterruptible sleep state is a sleep state that cannot handle a signal (such as waiting for disk or network IO (input/output)).
When the process is sleeping uninterruptibly, the signal will be noticed when the process returns from the system call or trap. – 这句是关键。 当处于uninterruptibly sleep 状态时,只有当进程从system 调用返回时,才通知signal。
A process which ends up in “D” state for any measurable length of time is trapped in the midst of a system call (usually an I/O operation on a device — thus the initial in the ps output).
Such a process cannot be killed — it would risk leaving the kernel in an inconsistent state, leading to a panic. In general you can consider this to be a bug in the device driver that the process is accessing.
SHOW PROFILES; +----------+------------+-------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-------------------------------------------------------------------------------+ | 10 | 0.00058000 | SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26'| | 11 | 0.00052500 | SELECT * FROM employees.titles WHERE emp_no='10001' AND title IN ... | +----------+------------+-------------------------------------------------------------------------------+
EXPLAIN SELECT * FROM employees.titles WHERE emp_no BETWEEN '10001' AND '10010' AND title='Senior Engineer' AND from_date BETWEEN '1986-01-01' AND '1986-12-31'; +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 16 | Using where | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
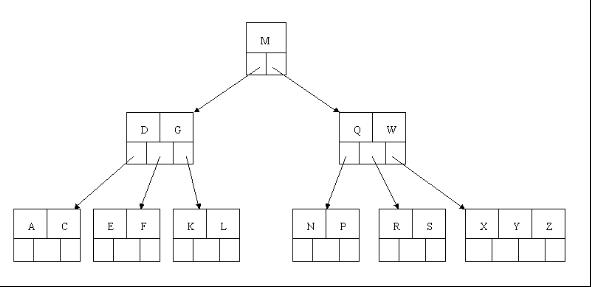
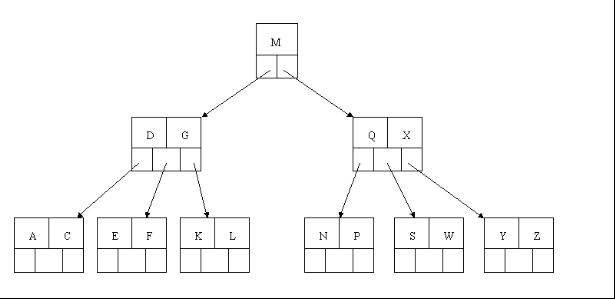
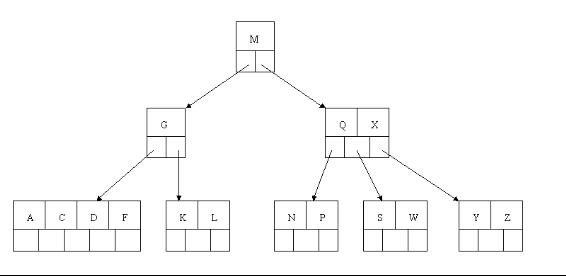
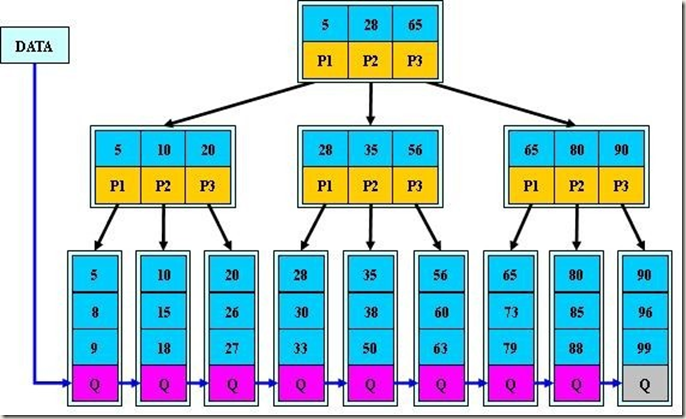
向相邻兄弟节点求借关键字步骤是因为当前的节点的关键子个数不符合M/2(取上限)-1 <= K <= M-1,此时可以看看与当前节点相邻的左右兄弟节点有没有丰满的,有的话,当前节点所对应的父节点的关键子下移到当前节点中,然后丰满兄弟节点的相应的关键子上移到父节点中,放在那个刚下移的关键子的位置上,结束!,如果左右兄弟节点都没有丰满的话,就只能进行节点合并了。节点合并先找出需要合并的左右兄弟节点,二选一,然后将父节点所对应的关键子下移与需要合并的两个节点组成新的节点,此时,父节点相当于删除了一个关键字,那么就需要对父节点进行进入向相邻兄弟节点求借关键字步骤了,一直递归知道B树结构平衡为止!
对于不了解相关知识的网民来说,由于系统默认使用的ISP提供的域名查询服务器查询国外的权威服务器时即被防火长城污染,进而使其缓存受到污染,因此默认情况下查询ISP的服务器就会获得虚假IP地址;而用户直接查询境外域名查询服务器(比如 Google Public DNS)时有可能会直接被防火长城污染,从而在没有任何防范机制的情况下仍然不能获得目标网站正确的IP地址。 因为TCP连接的机制可靠,防火长城理论上未对TCP协议下的域名查询进行污染,故现在能透过强制使用TCP协议查询真实的IP地址。而现实的情况是,防火长城对于真实的IP地址也可能会采取其它的手段进行封锁,或者对查询行为使用连接重置的方法进行拦截,故能否真正访问可能还需要其它翻墙的手段。
Full Cone NAT:所有来自同一个内部Tuple X的请求均被NAT转换至同一个外部Tuple Y,而不管这些请求是不是属于同一个应用或者是多个应用的。除此之外,当X-Y的转换关系建立之后,任意外部主机均可随时将Y中的地址和端口作为目标地址和目标端口,向内部主机发送UDP报文,由于对外部请求的来源无任何限制,因此这种方式虽然足够简单,但却不那么安全
unix提供了一种机制可以保证只要父进程想知道子进程结束时的状态信息, 就可以得到。这种机制就是: 在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。 但是仍然为其保留一定的信息(包括进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等)。直到父进程通过wait / waitpid来取时才释放。 但这样就导致了问题,如果进程不调用wait / waitpid的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
Linux Daemon(守护进程)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。它不需要用户输入就能运行而且提供某种服务,不是对整个系统就是对某个用户程序提供服务。Linux系统的大多数服务器就是通过守护进程实现的。常见的守护进程包括系统日志进程syslogd、 web服务器httpd、邮件服务器sendmail和数据库服务器mysqld等。
intmain(int argc, char *argv[]) { int fp; time_t t; char buf[] = {"This is a daemon: "}; char *datetime; int len = 0; //printf("The NOFILE is: %d\n", NOFILE); //printf("The tablesize is: %d\n", getdtablesize()); //printf("The pid is: %d\n", getpid());
// 初始化 Daemon 进程 init_daemon();
// 每隔一分钟记录运行状态 while (1) { if (-1 == (fp = open("/tmp/daemon.log", O_CREAT|O_WRONLY|O_APPEND, 0600))) { printf("Open file error !\n"); exit(1); } len = strlen(buf); write(fp, buf, len); t = time(0); datetime = asctime(localtime(&t)); len = strlen(datetime); write(fp, datetime, len); close(fp); sleep(60); }
DESCRIPTION The daemon() function is for programs wishing to detach themselves from the controlling terminal and run in the background as system daemons.
If nochdir is zero, daemon() changes the process’s current working directory to the root directory ("/"); otherwise,
If noclose is zero, daemon() redirects standard input, standard output and standard error to /dev/null; otherwise, no changes are made to these file descriptors.
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
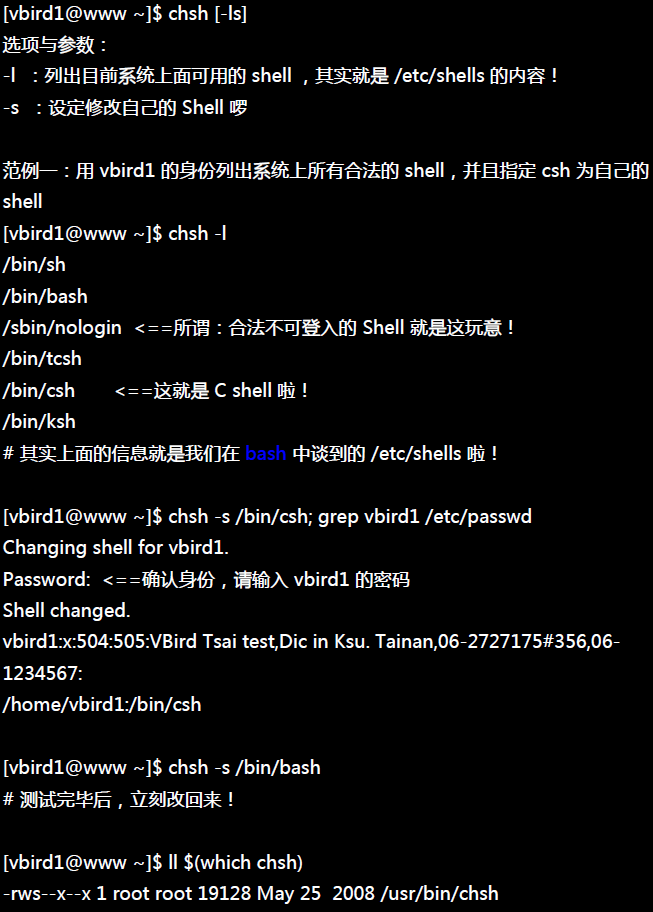
范例二:观察目前『已挂载』的文件系统,包括各文件系统的Label名称 [root@www ~]# mount -l /dev/hdc2 on / type ext3 (rw) [/1] proc on /proctypeproc (rw) sysfs on /sys type sysfs (rw) devpts on /dev/pts type devpts (rw,gid=5,mode=620) /dev/hdc3 on /home type ext3 (rw) [/home] /dev/hdc1 on /boot type ext3 (rw) [/boot] tmpfs on /dev/shm type tmpfs (rw) none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw) sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw) /dev/hdc6 on /mnt/hdc6 type ext3 (rw) [vbird_logical] # 除了实际的文件系统外,很多特殊的文件系统(proc/sysfs...)也会被显示出来! # 值得注意的是,加上 -l 可以列出如上特殊字体的标头(label)
另外,我们也可以利用 mount 来将某个目录挂载到另外一个目录去!这并不是挂载文件系统,而是额外挂载某个目录的方法! 虽然底下的方法也可以使用 symbolic link 来连结,不过在某些不支持符号链接的程序运作中,还是得要透过这样的方法才行。
1 2 3 4 5 6 7 8
范例七:将 /home 这个目录暂时挂载到 /mnt/home 底下: [root@www ~]# mkdir /mnt/home [root@www ~]# mount --bind /home /mnt/home [root@www ~]# ls -lid /home/ /mnt/home 2 drwxr-xr-x 6 root root 4096 Sep 2902:21 /home/ 2 drwxr-xr-x 6 root root 4096 Sep 2902:21 /mnt/home [root@www ~]# mount -l /home on /mnt/home type none(rw,bind)
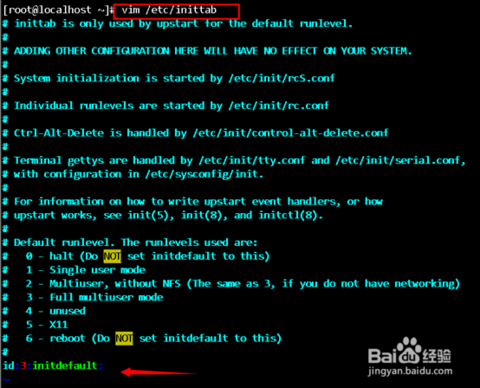
命令: chkconfig atd on 输出: [root@localhost /]# chkconfig atd on [root@localhost /]#
5.2 at 的运行方式
既然是计划任务,那么应该会有任务执行的方式,并且将这些任务排进行程表中。那么产生计划任务的方式是怎么进行的? 事实上,我们使用 at 这个命令来产生所要运行的计划任务,并将这个计划任务以文字档的方式写入 /var/spool/at/ 目录内,该工作便能等待 atd 这个服务的取用与运行了。就这么简单。不过,并不是所有的人都可以进行 at 计划任务。为什么? 因为系统安全的原因。很多主机被所谓的攻击破解后,最常发现的就是他们的系统当中多了很多的黑客程序, 这些程序非常可能运用一些计划任务来运行或搜集你的系统运行信息,并定时的发送给黑客。 所以,除非是你认可的帐号,否则先不要让他们使用 at 命令。那怎么达到使用 at 的可控呢?
我们可以利用 /etc/at.allow 与 /etc/at.deny 这两个文件来进行 at 的使用限制。加上这两个文件后, at 的工作情况是这样的:
先找寻 /etc/at.allow 这个文件,写在这个文件中的使用者才能使用 at ,没有在这个文件中的使用者则不能使用 at (即使没有写在 at.deny 当中);如果 /etc/at.allow 不存在,就寻找 /etc/at.deny 这个文件,若写在这个 at.deny 的使用者则不能使用 at ,而没有在这个 at.deny 文件中的使用者,就可以使用 at 命令了。
如果两个文件都不存在,那么只有 root 可以使用 at 这个命令。
透过这个说明,我们知道 /etc/at.allow 是管理较为严格的方式,而 /etc/at.deny 则较为松散 (因为帐号没有在该文件中,就能够运行 at 了)。在一般的 distributions 当中,由于假设系统上的所有用户都是可信任的, 因此系统通常会保留一个空的 /etc/at.deny 文件,意思是允许所有人使用 at 命令的意思 (您可以自行检查一下该文件)。 不过,万一你不希望有某些使用者使用 at 的话,将那个使用者的帐号写入 /etc/at.deny 即可! 一个帐号写一行。
ls -l |awk 'BEGIN {size=0;print "[start]sizeis", size} {if($5!=4096){size=size+$5;}} END{print "[end]sizeis", size/1024/1024,"M"}' [end]size is 8.22339 M
tee命令读取标准输入,把这些内容同时输出到标准输出和(多个)文件中(read from standard input and write to standard output and files. Copy standard input to each FILE, and also to standard output. If a FILE is -, copy again to standard output.)。在info tee中说道:tee命令可以重定向标准输出到多个文件(tee': Redirect output to multiple files. Thetee’ command copies standard input to standard output and also to any files given as arguments. This is useful when you want not only to send some data down a pipe, but also to save a copy.)。要注意的是:在使用管道线时,前一个命令的标准错误输出不会被tee读取。
常用参数
格式:tee
只输出到标准输出,因为没有指定文件嘛。
格式:tee file
输出到标准输出的同时,保存到文件file中。如果文件不存在,则创建;如果已经存在,则覆盖之。(If a file being written to does not already exist, it is created. If a file being written to already exists, the data it previously contained is overwritten unless the `-a’ option is used.)
输出到标准输出两次。(A FILE of -' causestee’ to send another copy of input to standard output, but this is typically not that useful as the copies are interleaved.)
-i, --install install package(s) -v, --verbose provide more detailed output -h, --hash print hash marks as package installs (good with -v) -e, --erase erase (uninstall) package -U, --upgrade=<packagefile>+ upgrade package(s) --replacepkge 无论软件包是否已被安装,都强行安装软件包 --test 安装测试,并不实际安装 --nodeps 忽略软件包的依赖关系强行安装 --force 忽略软件包及文件的冲突
Query options (with -q or --query): -a, --all query/verify all packages -p, --package query/verify a package file -l, --list list files in package -d, --docfiles list all documentation files -f, --file query/verify package(s) owning file
#include<iostream> #include<cstring> #include<algorithm> usingnamespacestd; #define N 52 int dp[105][N][N],map[N][N]; intmain() { int test; cin>>test; while(test--) { int m,n; cin>>m>>n; int i,j; for(i=1;i<=m;++i) for(j=1;j<=n;++j) cin>>map[i][j];
memset(dp,0,sizeof(dp)); int all=m+n; int k,t1=0,t2=0,ans=0; int x1,y1,x2,y2;
#include<iostream> #include<cstring> #include<algorithm> usingnamespacestd; #define N 52 int dp[2][N][N],map[N][N]; intmain() { int test; cin>>test; while(test--) { int m,n; cin>>m>>n; int i,j; for(i=1;i<=m;++i) for(j=1;j<=n;++j) cin>>map[i][j];
memset(dp,0,sizeof(dp)); int all=m+n; int k,t1=0,t2=0,ans=0; int x1,y1,x2,y2;
#include<iostream> #include<cstring> #include<algorithm> usingnamespacestd; #define N 52 int dp[105][N][N],map[N][N]; intmain() { int test; cin>>test; while(test--) { int m,n; cin>>m>>n; int i,j; for(i=1;i<=m;++i) for(j=1;j<=n;++j) cin>>map[i][j];
memset(dp,0,sizeof(dp)); int all=m+n; int k,t1=0,t2=0,ans=0; int x1,y1,x2,y2;
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.

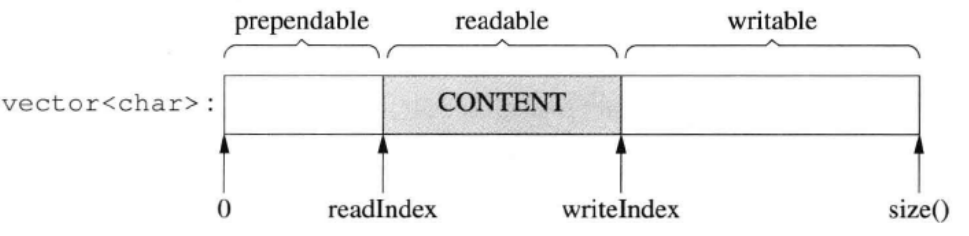
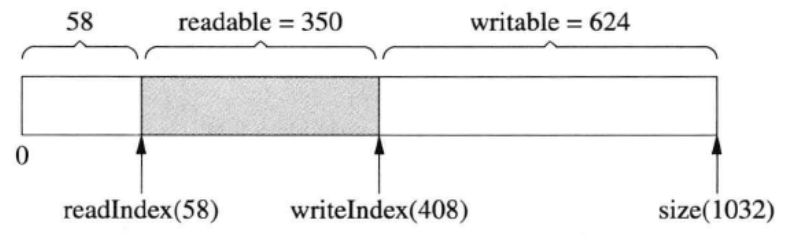
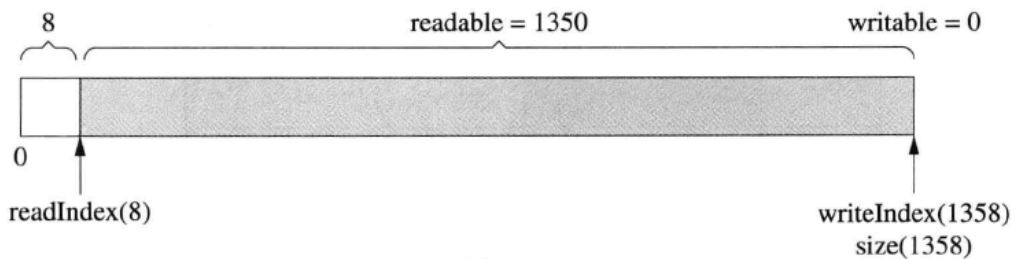



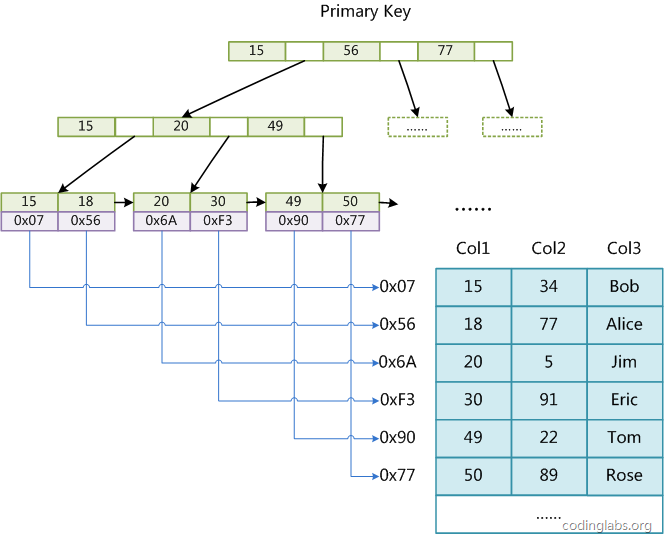
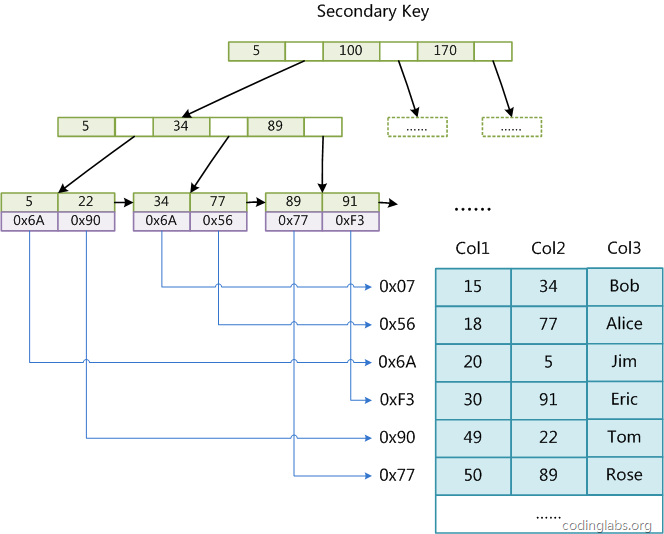
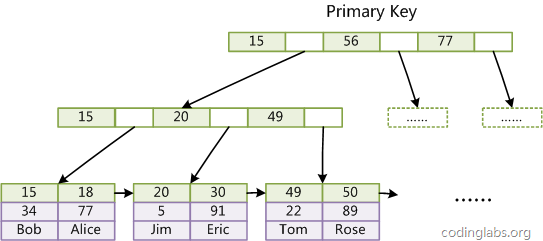
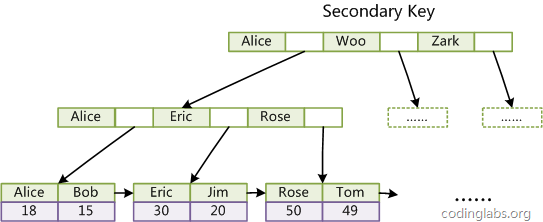
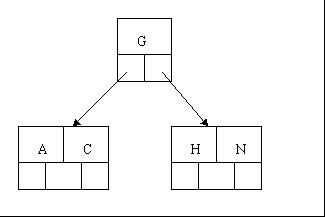
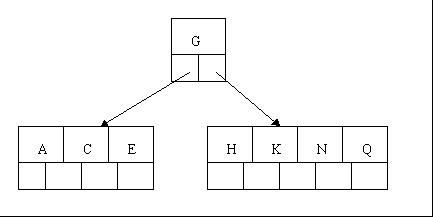
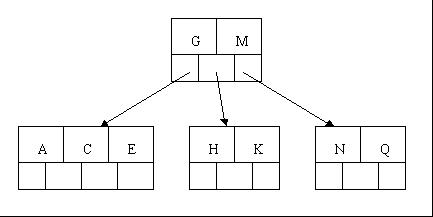
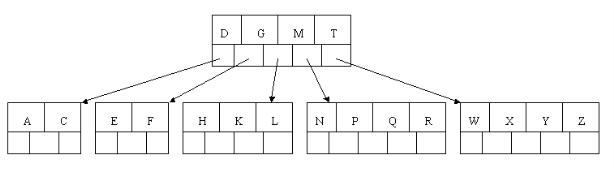
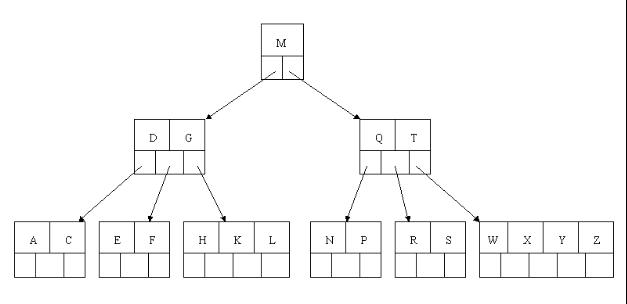
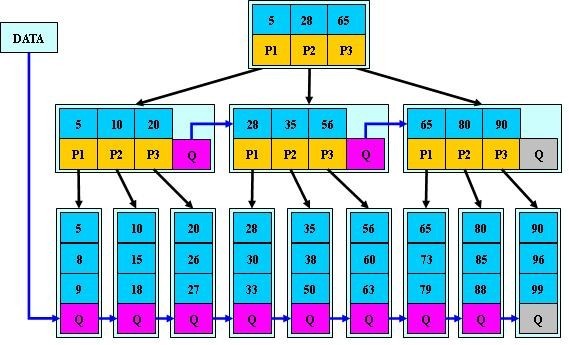
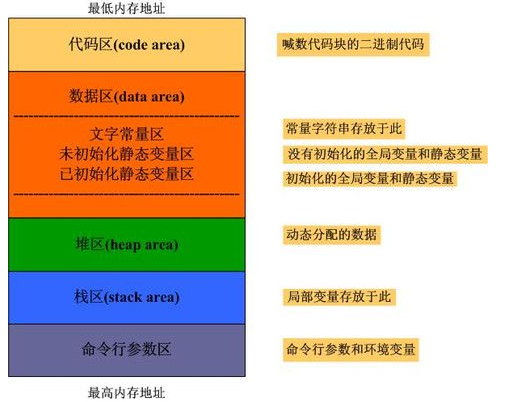
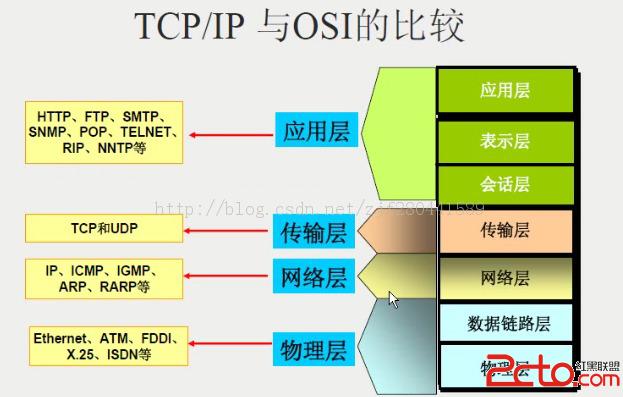
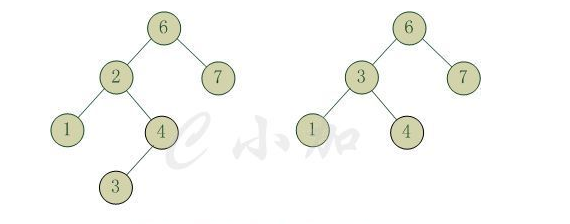
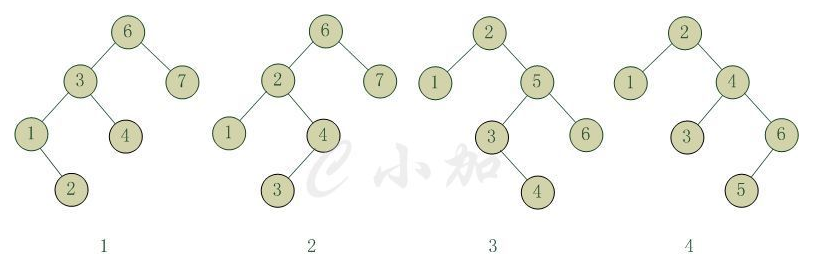
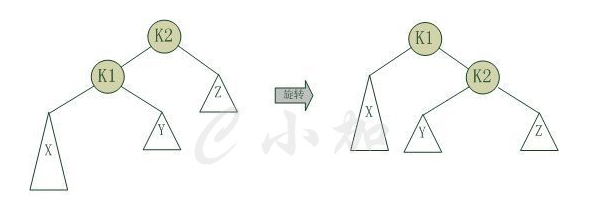
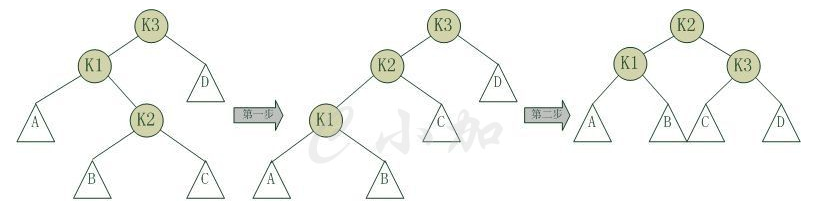
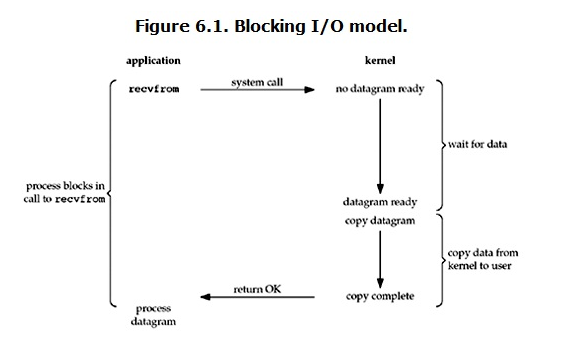
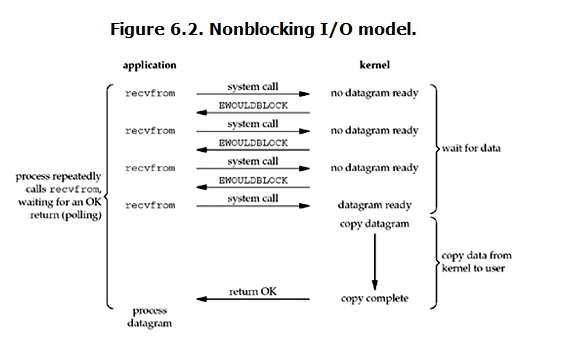
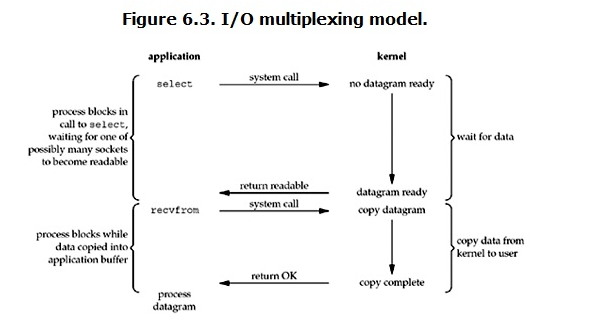
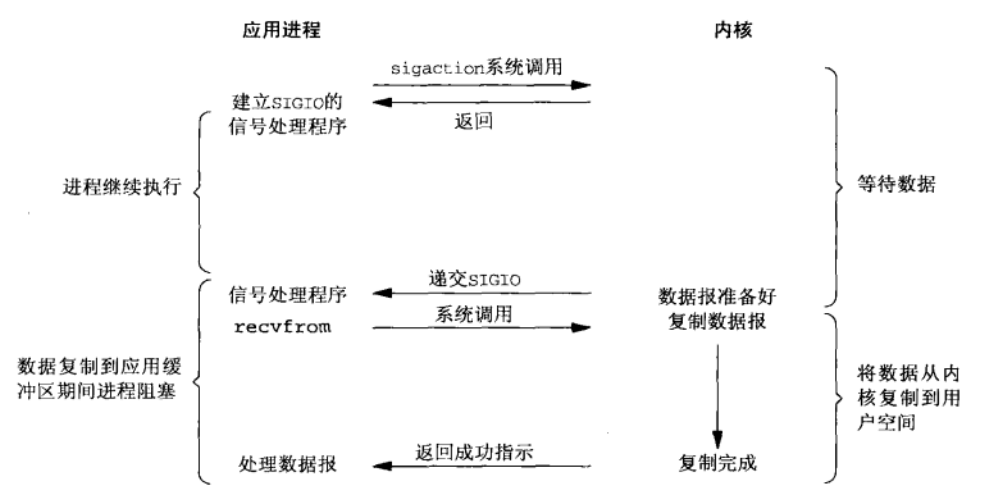
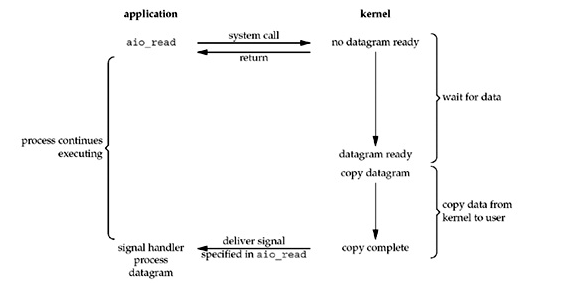







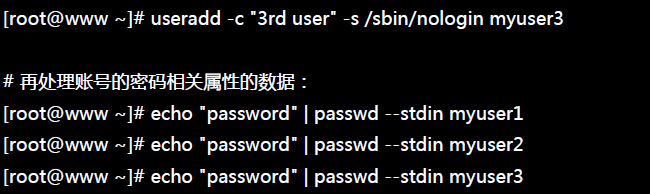
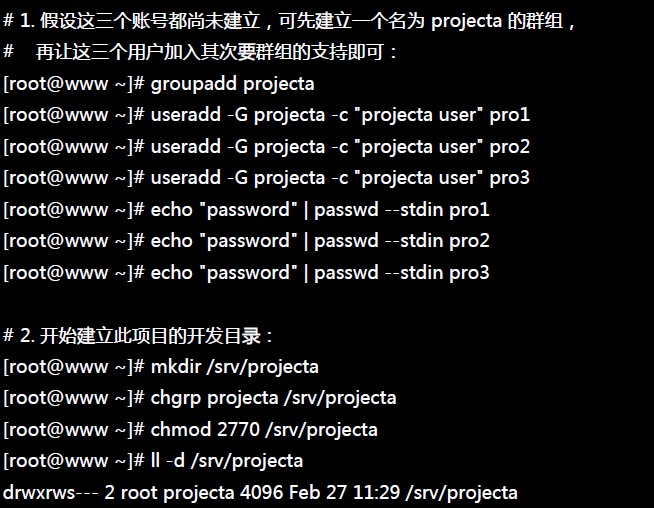




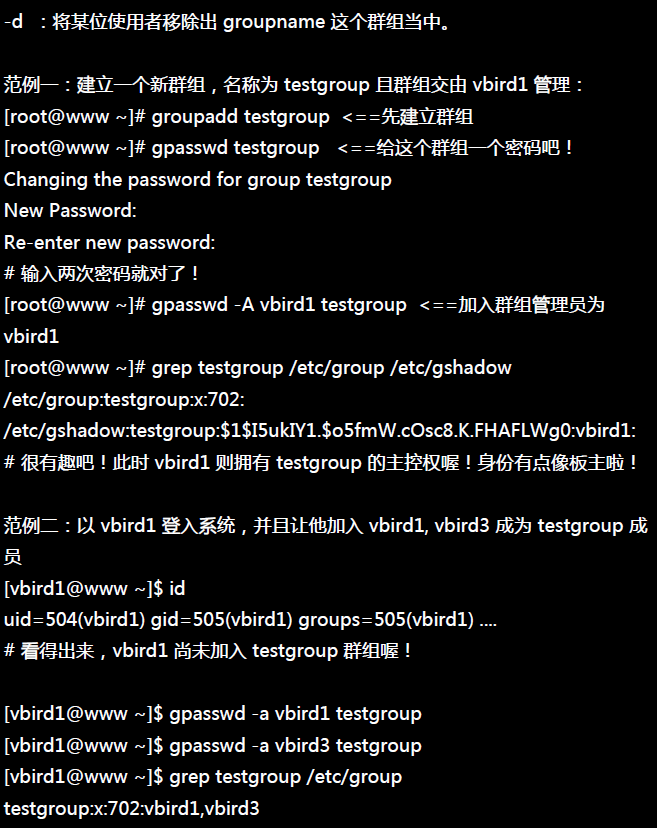





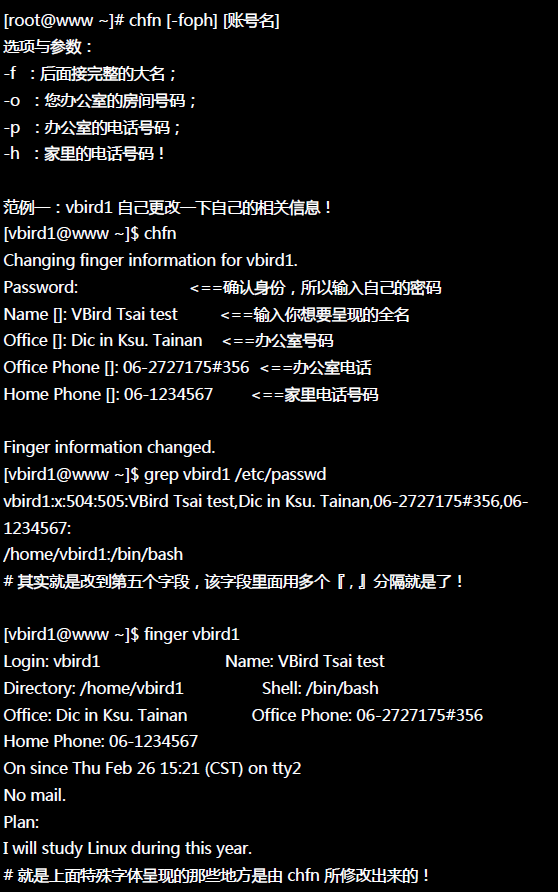
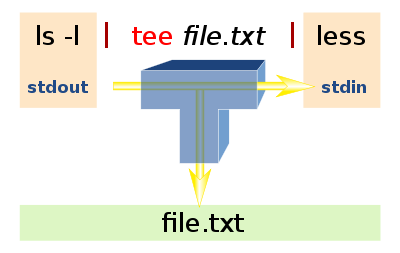 tee过滤器用来想多个目标发送输出的内容。如果用于管道的话,他可以将输出复制一份到文件,兵复制另外一份到屏幕上(或一些其他的程序)。
tee过滤器用来想多个目标发送输出的内容。如果用于管道的话,他可以将输出复制一份到文件,兵复制另外一份到屏幕上(或一些其他的程序)。